近日,英偉達(dá)(NVIDIA)的掌舵人黃仁勛與一家備受矚目的中國AI初創(chuàng)企業(yè)——MiniMax(希宇科技)的創(chuàng)始人閆俊杰進(jìn)行了一場長達(dá)兩小時的私密會晤。據(jù)悉,閆俊杰是唯一獲此殊榮的中國AI創(chuàng)業(yè)公司創(chuàng)始人,與黃仁勛共同探討了中美AI行業(yè)的現(xiàn)狀與未來趨勢。
MiniMax由閆俊杰于2021年創(chuàng)立,他此前曾任商湯科技的高管職位。這家新興企業(yè)在AI領(lǐng)域迅速嶄露頭角,特別是在大規(guī)模混合架構(gòu)推理模型方面取得了顯著成就。
今年6月,MiniMax震撼發(fā)布了全球首個開源的大規(guī)模混合架構(gòu)推理模型M1。該模型不僅在性能上超越了國內(nèi)的閉源模型,逼近了DeepSeek R1及海外頂尖模型的水平,更以卓越的效率和高性價比贏得了業(yè)界的廣泛關(guān)注。
MiniMax的M1模型得益于其獨(dú)創(chuàng)的Lightning Attention機(jī)制,這一機(jī)制在計(jì)算注意力矩陣時表現(xiàn)出色,大幅提升了訓(xùn)練和推理效率。因此,M1模型在處理長上下文輸入和深度推理任務(wù)時具有顯著優(yōu)勢,支持業(yè)內(nèi)最高的100萬上下文輸入,以及長達(dá)8萬Token的推理輸出。
在算力使用方面,M1模型同樣表現(xiàn)出色。在進(jìn)行8萬Token深度推理時,其算力需求僅為DeepSeek R1的約30%。這一特性使得MiniMax在訓(xùn)練和推理階段都擁有巨大的算力效率優(yōu)勢。
MiniMax還提出了創(chuàng)新的強(qiáng)化學(xué)習(xí)算法CISPO,通過裁剪重要性采樣權(quán)重來提升學(xué)習(xí)效率。在AIME實(shí)驗(yàn)中,CISPO的收斂性能顯著優(yōu)于包括字節(jié)近期提出的DAPO在內(nèi)的多種強(qiáng)化學(xué)習(xí)算法,甚至超越了DeepSeek早期使用的GRPO。
得益于這些技術(shù)創(chuàng)新,MiniMax的強(qiáng)化訓(xùn)練過程異常高效,遠(yuǎn)遠(yuǎn)超出了預(yù)期。整個強(qiáng)化學(xué)習(xí)階段僅使用了512塊H800 GPU,耗時三周,租賃成本僅為53.47萬美金,比最初預(yù)算少了一個數(shù)量級。
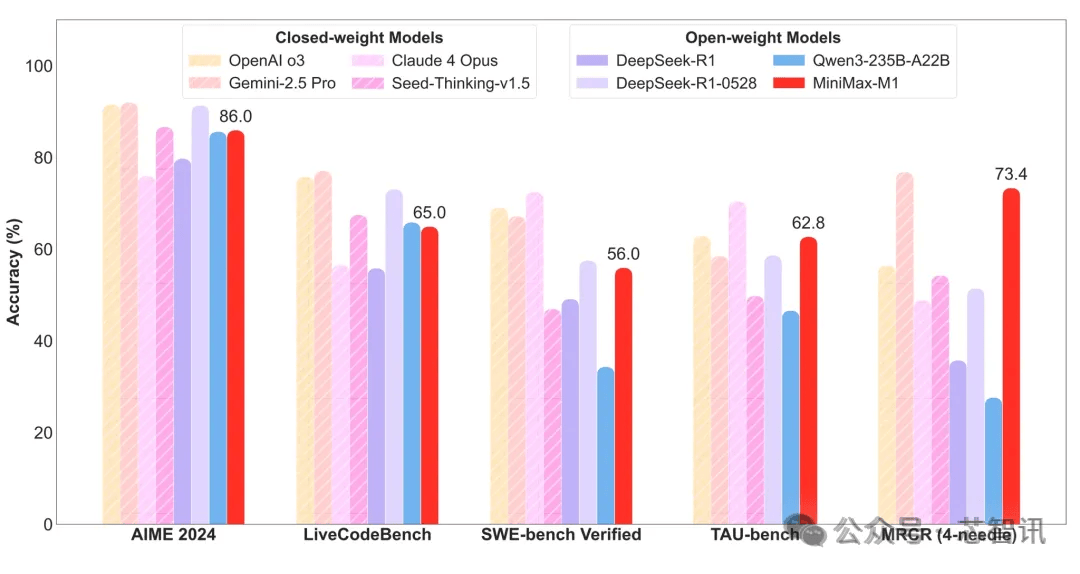
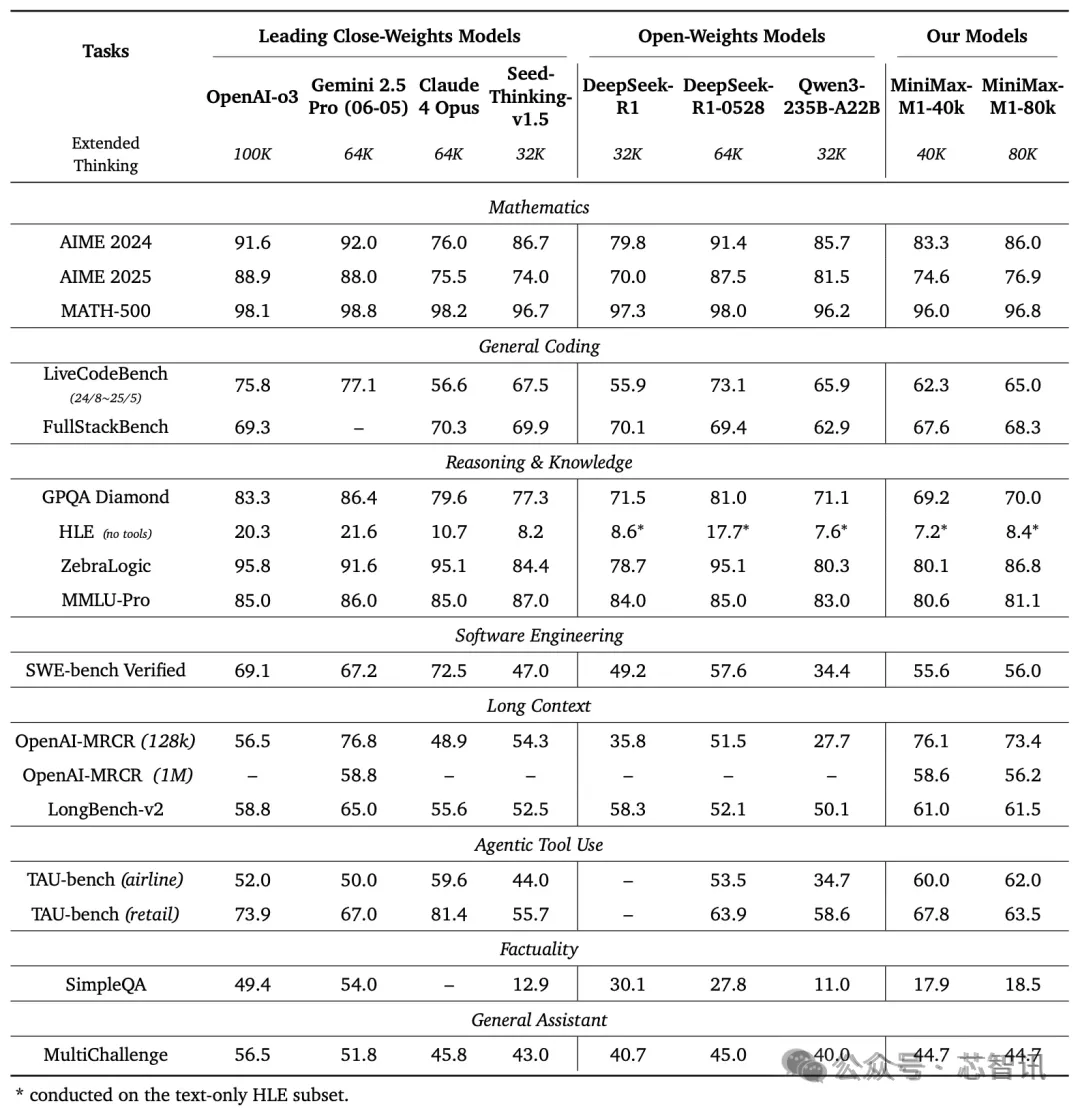
在業(yè)內(nèi)主流的17個評測集上,MiniMax對M1進(jìn)行了詳細(xì)評測。結(jié)果顯示,M1在長上下文理解任務(wù)中表現(xiàn)出色,僅以微弱差距落后于Google的Gemini 2.5 Pro,但在代理工具使用場景(TAU-bench)中卻戰(zhàn)勝了后者。
鑒于M1模型的高效訓(xùn)練和推理算力使用,MiniMax宣布在MiniMax APP和Web平臺上提供不限量免費(fèi)使用服務(wù)。同時,公司還以業(yè)內(nèi)最低價格在官網(wǎng)上提供API服務(wù),價格根據(jù)輸入長度的不同而有所差異,但均比DeepSeek-R1更具性價比。