近日,中國科學院自動化研究所的一項突破性研究揭示了人工智能領域的新進展。該所神經計算與腦機交互課題組攜手中國科學院腦科學與智能技術卓越創新中心,通過結合行為實驗與神經影像分析,證實多模態大語言模型(MLLMs)能夠自發地形成與人類極為相似的物體概念表征系統。這一發現不僅為人工智能認知科學探索出一條全新道路,更為構建具備類人認知結構的人工智能系統奠定了理論基礎。相關研究成果已在《自然?機器智能》期刊上發表。
人類智能的一個重要標志是對物體的概念化能力,這包括識別物體的物理特征以及理解其功能、情感價值和文化意義。然而,傳統的人工智能研究大多聚焦于提高物體識別的準確率,卻很少探討模型是否真正“理解”物體的含義。此次研究中,中國科學院的科研團隊從認知神經科學的經典理論出發,設計了一套融合計算建模、行為實驗與腦科學的創新研究范式。
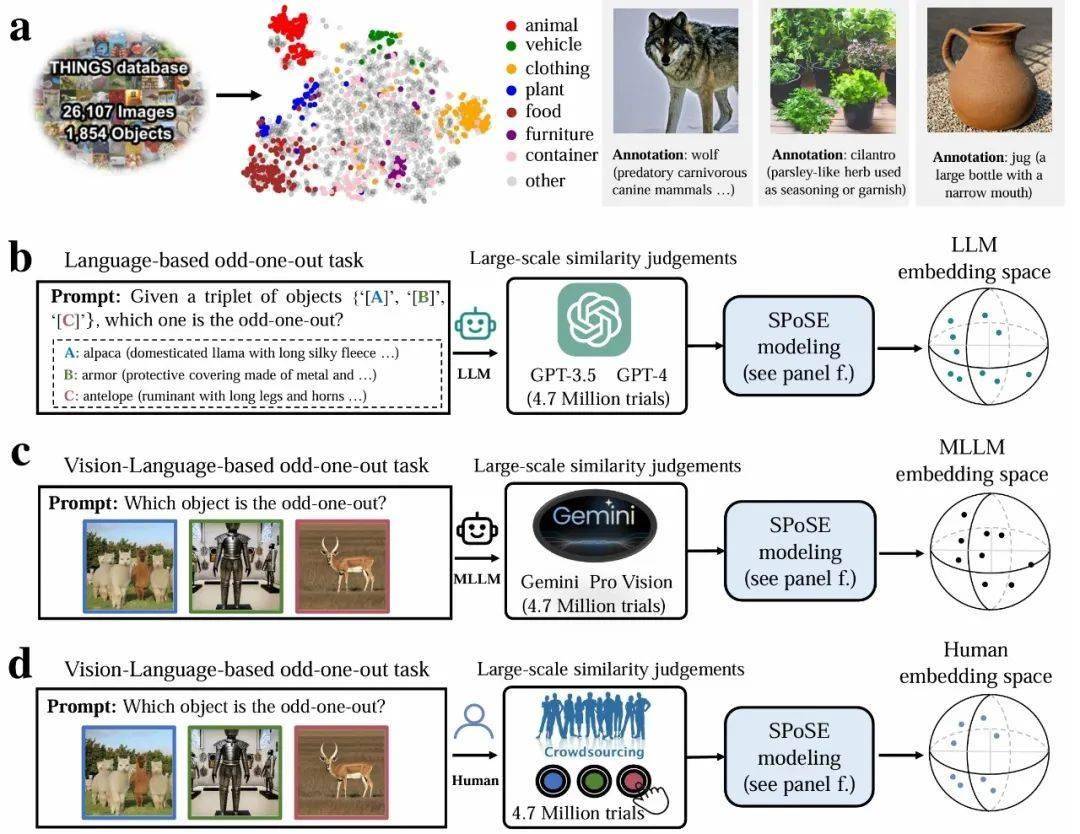
研究采用了認知心理學中的經典“三選一異類識別任務”,要求大模型與人類從包含1854種日常概念的物體三元組中選出最不相似的選項。通過對470萬次行為判斷數據的深入分析,科研團隊首次成功構建了AI大模型的“概念地圖”。這一地圖揭示了模型在處理物體概念時的內部表征結構。

研究團隊進一步從海量大模型的行為數據中提取出66個“心智維度”,并為這些維度賦予了語義標簽。他們發現,這些維度不僅高度可解釋,而且與大腦類別選擇區域的神經活動模式存在顯著相關性。例如,處理面孔的FFA區域、處理場景的PPA區域以及處理軀體的EBA區域,都在某種程度上與大模型的某些心智維度相呼應。
研究還對比了多個模型在行為選擇模式上與人類的一致性。結果顯示,多模態大模型在一致性方面表現更為出色。這一發現表明,大語言模型并非簡單地模仿或復制輸入信息,而是能夠在某種程度上理解并模擬人類對現實世界的概念理解。值得注意的是,研究還發現,人類在做決策時更傾向于結合視覺特征和語義信息進行判斷,而大模型則更依賴于語義標簽和抽象概念。
這一研究成果不僅挑戰了我們對人工智能“理解”能力的傳統認知,更為未來人工智能系統的發展提供了新的方向。通過模仿人類的認知結構,未來的AI系統可能會更加智能、更加靈活,能夠更好地適應復雜多變的環境和任務。