近日,阿里通義千問團隊正式揭曉了其最新研發(fā)成果——視覺推理模型QVQ-Max,這一創(chuàng)新技術(shù)的推出標志著AI在視覺信息處理領(lǐng)域邁出了重要一步。
QVQ-Max模型的問世,旨在彌補傳統(tǒng)AI在視覺感知與認知推理結(jié)合方面的短板。通過一系列技術(shù)優(yōu)化,該模型顯著提升了從圖像、視頻等視覺信息中提取關(guān)鍵特征并進行深度推理的能力。
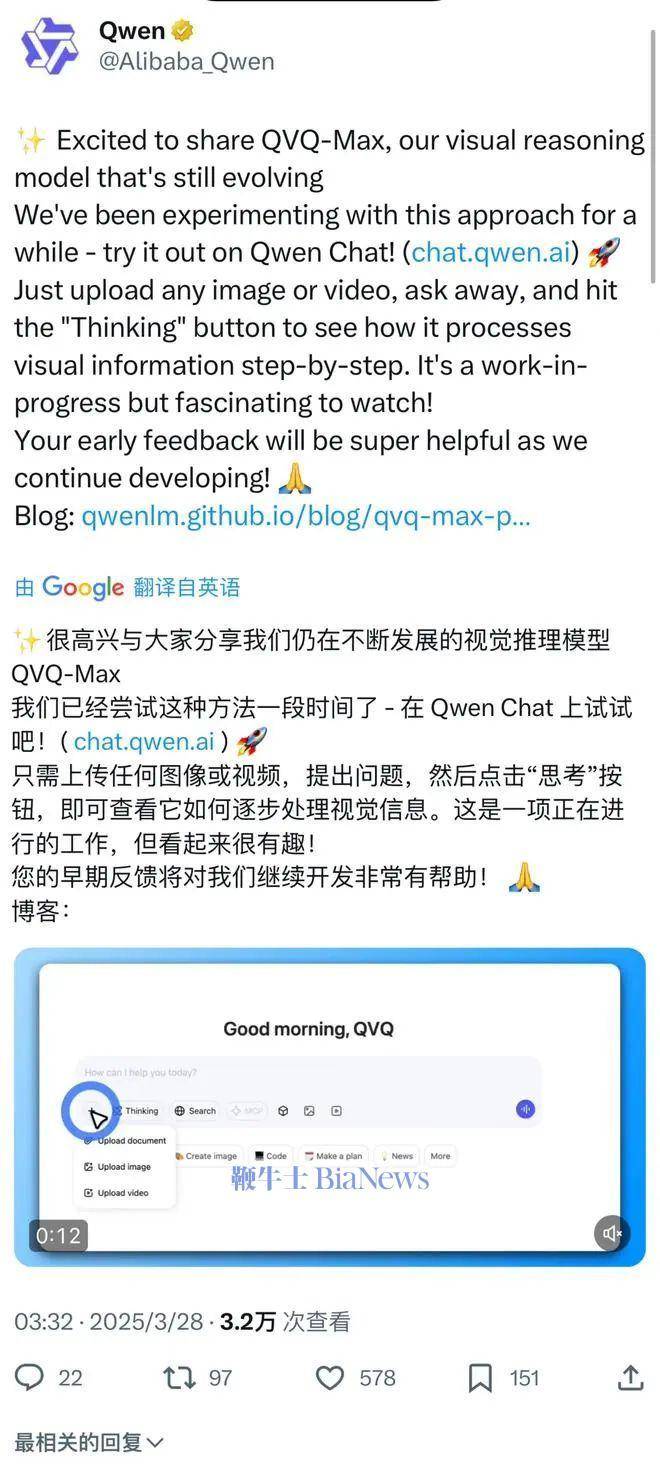
據(jù)了解,QVQ-Max不僅支持圖像與文本的聯(lián)合推理,還能處理視頻內(nèi)容,實現(xiàn)了多媒體信息的全面整合與分析。這一特性使得QVQ-Max在多個應(yīng)用場景中展現(xiàn)出巨大潛力。
在設(shè)計領(lǐng)域,QVQ-Max能夠根據(jù)用戶需求自動生成設(shè)計插圖,不僅節(jié)省了設(shè)計師的大量時間,還帶來了更多創(chuàng)意靈感。在短視頻制作方面,該模型能夠智能生成劇本,為內(nèi)容創(chuàng)作者提供便捷高效的創(chuàng)作工具。
更令人矚目的是,QVQ-Max還具備角色扮演內(nèi)容的創(chuàng)建能力。用戶可以根據(jù)自己的需求,定制專屬的角色和情節(jié),享受前所未有的個性化娛樂體驗。這一功能的推出,無疑將為用戶帶來更加豐富多元的互動娛樂方式。