在AI界掀起巨浪的DeepSeek R1,自其誕生以來的128天里,已對整個大模型市場造成了深遠(yuǎn)影響。這款模型以驚人的力量,推動了推理模型價格的急劇下滑,使得OpenAI在六月更新的o3價格相較于o1版本,直接降至兩成。
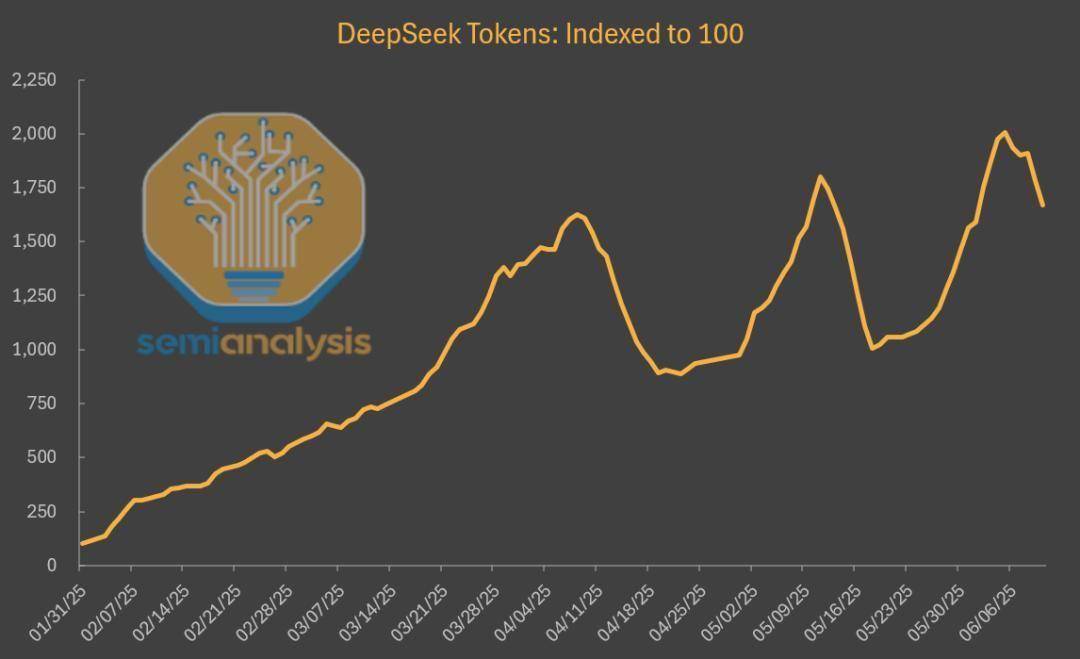
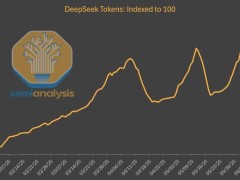
值得注意的是,DeepSeek模型的托管使用量在第三方平臺上呈現(xiàn)出爆炸式增長,與初發(fā)布時相比,幾乎激增了20倍,這一變化極大地促進(jìn)了眾多云計算企業(yè)的發(fā)展。然而,令人意外的是,DeepSeek自家的網(wǎng)站和API市場份額卻并未隨之水漲船高,反而出現(xiàn)了下滑趨勢,與上半年AI產(chǎn)品的持續(xù)增長態(tài)勢形成了鮮明對比。

據(jù)SemiAnalysis發(fā)布的一份深度報告分析,DeepSeek不僅改變了AI模型市場的競爭格局,也揭示了當(dāng)前AI市場份額的最新動態(tài)。盡管DeepSeek V3與R1模型經(jīng)過迭代升級,性能較1月發(fā)布時有了顯著提升,且價格更為親民,但其官方平臺的使用情況卻并未因此受益。
數(shù)據(jù)顯示,截至5月,全網(wǎng)DeepSeek模型生成的token中,僅有16%來自DeepSeek官方平臺。同時,其網(wǎng)頁版聊天機(jī)器人的流量也遭遇了大幅下滑,而與此同時,其他主要大模型的網(wǎng)頁版流量卻在持續(xù)攀升。這種“墻內(nèi)開花墻外香”的現(xiàn)象背后,實(shí)則隱藏著DeepSeek為降低成本所做的諸多妥協(xié)。
SemiAnalysis指出,用戶在DeepSeek官方平臺上使用模型時,往往需要等待數(shù)秒才能看到首個字符的出現(xiàn),這一延遲現(xiàn)象在業(yè)內(nèi)被稱為“首token延遲”。相比之下,盡管其他平臺的價格普遍更高,但其響應(yīng)速度卻快得多,部分平臺甚至能實(shí)現(xiàn)幾乎零延遲的體驗(yàn)。例如,在Parasail或Friendli等平臺,用戶僅需支付3-4美元,即可獲得幾乎沒有延遲的100萬token額度。而若選擇更大更穩(wěn)定的服務(wù)商,如微軟Azure平臺,雖然其價格是DeepSeek官方的2.5倍,但延遲卻減少了整整25秒。
DeepSeek官方甚至不是同等延遲條件下價格最低的DeepSeek模型服務(wù)商。在價格與性能的權(quán)衡上,DeepSeek選擇了在有限的推理計算資源下,僅提供64k的上下文窗口服務(wù),這在主流模型提供商中屬于最小之一。對于需要讀取整個代碼庫的編程場景而言,64K的上下文窗口顯然不夠用,用戶因此更傾向于選擇第三方平臺。而在同等價格下,Lambda和Nebius等平臺能提供2.5倍以上的上下文窗口。
DeepSeek為了降低成本,還將多個用戶的請求打包處理,雖然每個token的成本因此降低,但每個用戶的等待時間卻相應(yīng)增加。這一系列降本策略均顯示出DeepSeek目前對用戶體驗(yàn)的重視程度不高,其更多地將算力資源投入到內(nèi)部研發(fā)中,以實(shí)現(xiàn)AGI為目標(biāo)。同時,通過開源策略,DeepSeek鼓勵其他云服務(wù)托管其模型,以此擴(kuò)大影響力和培養(yǎng)生態(tài)。
在DeepSeek的影響下,其他大模型供應(yīng)商也開始調(diào)整策略。Claude為了緩解算力緊張的問題,降低了輸出速度,但仍努力在用戶體驗(yàn)與營收之間尋找平衡。自Claude 4 Sonnet發(fā)布以來,其輸出速度已下降了40%,但仍比DeepSeek快不少。Claude模型被設(shè)計成生成更簡潔的回復(fù),相同問題下,DeepSeek和Gemini可能需要多花3倍的token。
種種跡象表明,大模型供應(yīng)商正在從多個維度對模型進(jìn)行改進(jìn),不僅追求模型智能上限的提升,更注重每個token所能提供的智能價值。