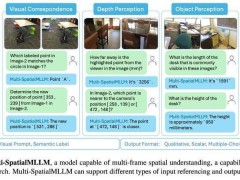
近日,科技界傳來一項(xiàng)重要進(jìn)展,meta公司與香港中文大學(xué)攜手,在人工智能領(lǐng)域邁出了關(guān)鍵一步。他們共同推出的Multi-SpatialMLLM模型,實(shí)現(xiàn)了對(duì)深度感知、視覺對(duì)應(yīng)和動(dòng)態(tài)感知三大功能的整合,打破了單幀圖像分析的局限性。
近年來,多模態(tài)大語(yǔ)言模型(MLLMs)在視覺任務(wù)處理方面取得了顯著成果。然而,作為獨(dú)立的數(shù)字實(shí)體,MLLMs的實(shí)際應(yīng)用卻受到了一定限制。隨著機(jī)器人、自動(dòng)駕駛等領(lǐng)域的快速發(fā)展,對(duì)MLLMs的空間理解能力提出了更高要求。但遺憾的是,現(xiàn)有的模型在基礎(chǔ)空間推理任務(wù)中表現(xiàn)并不理想,例如,它們常常無法準(zhǔn)確區(qū)分左右。
針對(duì)這一難題,meta旗下的FAIR團(tuán)隊(duì)與香港中文大學(xué)展開了深入研究。他們發(fā)現(xiàn),過去的研究往往將問題歸咎于缺乏專門的訓(xùn)練數(shù)據(jù),并試圖通過單張圖像的空間數(shù)據(jù)進(jìn)行改進(jìn)。然而,這種方法只能局限于靜態(tài)視角的分析,缺乏動(dòng)態(tài)信息處理的能力。
為了解決這個(gè)問題,F(xiàn)AIR團(tuán)隊(duì)與香港中文大學(xué)聯(lián)合推出了MultiSPA數(shù)據(jù)集。這個(gè)數(shù)據(jù)集包含了超過2700萬(wàn)個(gè)樣本,涉及多樣化的3D和4D場(chǎng)景,為MLLMs的訓(xùn)練提供了豐富的資源。MultiSPA數(shù)據(jù)集結(jié)合了Aria Digital Twin、Panoptic Studio等高質(zhì)量標(biāo)注場(chǎng)景數(shù)據(jù),并通過GPT-4o生成了多樣化的任務(wù)模板,從而確保了數(shù)據(jù)的全面性和多樣性。
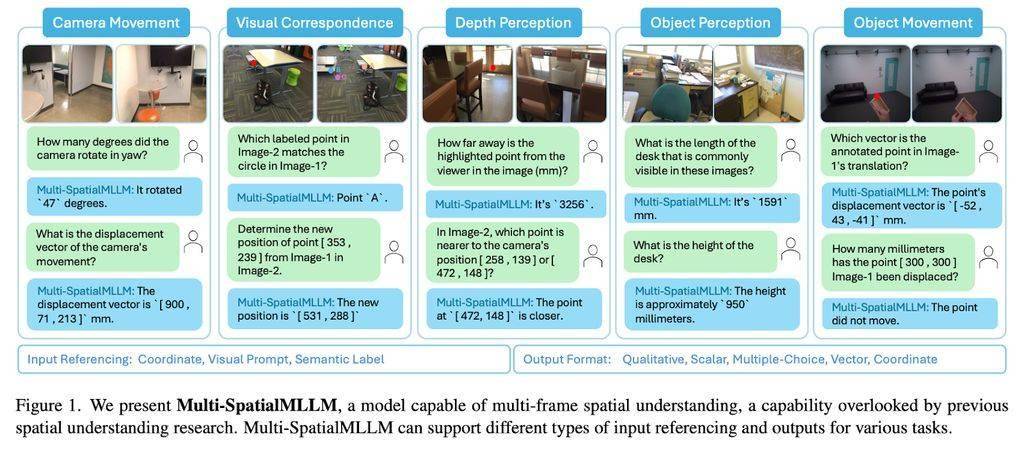
在MultiSPA數(shù)據(jù)集的基礎(chǔ)上,研究團(tuán)隊(duì)設(shè)計(jì)了五個(gè)訓(xùn)練任務(wù),包括深度感知、相機(jī)移動(dòng)感知、物體大小感知等。這些任務(wù)旨在提升Multi-SpatialMLLM模型在多幀空間推理上的能力,使其能夠更好地理解和處理復(fù)雜的空間信息。

經(jīng)過嚴(yán)格的測(cè)試和評(píng)估,Multi-SpatialMLLM模型展現(xiàn)出了卓越的性能。在MultiSPA基準(zhǔn)測(cè)試中,該模型相比基礎(chǔ)模型平均提升了36%,在定性任務(wù)上的準(zhǔn)確率達(dá)到80%-90%,遠(yuǎn)超基礎(chǔ)模型的50%。甚至在預(yù)測(cè)相機(jī)移動(dòng)向量等高難度任務(wù)上,該模型也取得了18%的準(zhǔn)確率。在BLINK基準(zhǔn)測(cè)試中,Multi-SpatialMLLM模型的準(zhǔn)確率接近90%,平均提升26.4%,超越了多個(gè)專有系統(tǒng)。
Multi-SpatialMLLM模型在保持原有性能的同時(shí),還展現(xiàn)出了不依賴過度擬合空間推理任務(wù)的通用能力。在標(biāo)準(zhǔn)視覺問答(VQA)測(cè)試中,該模型依然保持了出色的表現(xiàn)。這一成果不僅為MLLMs在空間理解方面的發(fā)展提供了新的思路和方法,也為機(jī)器人、自動(dòng)駕駛等領(lǐng)域的未來發(fā)展奠定了堅(jiān)實(shí)的基礎(chǔ)。